


生命科学150多年来经历了环环相扣的三轮革命,研究范式发生着深刻变化,从生物表观性状及遗传的观察描述到生命过程的分子生物学表征与关联,再到以组学为特征的系统生物学运用,为合成生物学的兴起提供了坚实的学科基础[1]。合成生物学发展20余年,取得了系列突破性进展,创新应用逐步实现,学科体系构建渐成。
1 合成生物学内涵与外延
合成生物学(synthetic biology)以生物科学为基础,会聚化学、物理、信息等学科,融合工程学原理,设计改造天然的或合成新的生物体,揭示生命运行规律(造物致知)、变革生物体系工程化应用(造物致用),又称工程生物学(engineering biology)[2]。合成生物学的内涵和外延不断拓展,涵盖基础理论、使能技术及创新应用等研究方向,推动交叉学科研究创新发展。
合成生物学基于生命科学发展而来,与传统生物学既密切关联,又有所区别[3]。传统生物学主要以自然界生物体为研究对象,利用观察、实验、分析和推理等科学方法,运用先进的仪器和设备,采用多种技术和手段,获取和处理大量的生物数据,建立和验证生物模型和理论,探索生命的本质和规律。技术的发展使得人们对生命体进行系统性工程化改造成为可能。有别于传统对生命体多样化、复杂化和自适应等认识,合成生物学尝试借鉴工程学标准化、模块化和可设计等原则,自下而上地对生命体进行优化设计改造。随着生物建模与模拟、大规模基因组合成与组装、新一代基因编辑工具等技术的发展,尤其是近年来人工智能(artificial intelligence, AI)对于生物设计创新应用的不断涌现,合成生物使能技术获得了飞速发展,其创新应用在医药健康、生物工业、生物农业、生物能源、环境修复、生物材料,以及生物电子与生物信息等领域逐渐显示出巨大的赋能作用(表1)。
表1 合成生物学与生物技术的关联与区别
Table 1
| 比较 | 生物技术 | 合成生物学 |
|---|---|---|
| 属性 | 利用生物体系造福人类,属于基因产业 | 利用生物体系造福人类,属于基因产业 |
| 应用 | 医药健康、生物工业、生物农业、生物能源、环境修复、生物材料、生物电子与生物信息,等 | 医药健康、生物工业、生物农业、生物能源、环境修复、生物材料、生物电子与生物信息,等 |
| 手段 | 单个外源基因的克隆与表达 | 生物设计、大规模基因组合成与组装、基因网络编辑、底盘细胞、人工智能(黑箱模型)与生物智造 |
| 形式 | 一个基因,一个产业:乙肝疫苗、胰岛素、干扰素、抗体药基因修饰作物,等 | 生物设计,多基因协同:合成疫苗及药物、精准细胞治疗、复杂代谢产品、基因网络育种、新功能生物电子、生物传感、生物材料,等 |
| 能力 | 初级 | 高级 |
2 合成生物学发展脉络
100年多前法国学者提出人工模拟合成细胞的理念,并首次使用了“合成生物学”一词[4]。20世纪中叶,美国和中国学者相继实现DNA、RNA和蛋白质等生物大分子的人工体外合成。1965年,中国科学家实现牛胰岛素的全合成。1966年,美国学者合成了多聚核苷酸。1981年,中国学者全合成酵母丙氨酸tRNA,这也是首次人工合成的具有生物学功能的核糖核酸,为后来人工合成基因组积累了重要经验[2]。20世纪七八十年代,分子克隆和PCR的进步,使得基因操作在微生物学研究中得到广泛的应用,为人工基因调控与设计提供了基础的技术手段,但这个时期的基因工程往往局限于克隆和重组基因表达,在微生物中发挥作用的广度和深度仍然有限。20世纪90年代中期,自动化DNA测序技术的进步和计算工具的改良,使得研究人员能够测序完整的微生物基因组。同时,高通量技术的发展,使得研究人员获得了大量关于细胞成分及其相互作用的数据。这些技术的进步为理解生命的复杂性提供了新的视角。随着生物实验研究与计算分析相结合,分子生物学的“大规模化”研究促进了系统生物学领域的发展。在此基础上,作为“自上而下”系统生物学方法的补充,研究人员提出了一种“自下而上”的工程学方法。到20世纪90年代末,这种“自下而上”的工程学方法开始在分子生物学领域得到应用,为具有天然工程特性的合成生物学奠定了基础[5]。
纪初,合成生物学进入新的研究发展阶段,真正被广泛关注。在Web of Science以“synthetic-biology”为关键词检索,合成生物学领域已有近2万篇论文,期刊学术出版物逐年增加,系列重要成果频频涌现。合成生物学发展脉络大致可以概括为三个方向:一是使能技术的系列突破,如基因线路设计、基因组合成与组装、基因组编辑、底盘细胞构建、无细胞转化体系、蛋白质从头设计、非天然体系及生物正交、人工智能的应用等;二是生物体基因组合成与组装能力的迭代提升,目前已经实现原核生物基因组和酵母染色体合成,正在挑战多细胞生物染色体合成;三是细胞工厂和新生物系统的构建与应用,一方面涉及“造物致知”,即自下而上构建生物体系以理解生物学基本原理;另一方面可概括为“造物致用”,覆盖生物医药、生物农业、生物化工、生物能源、生物环保、生物材料,以及生物电子与生物信息等(图1)。
图1
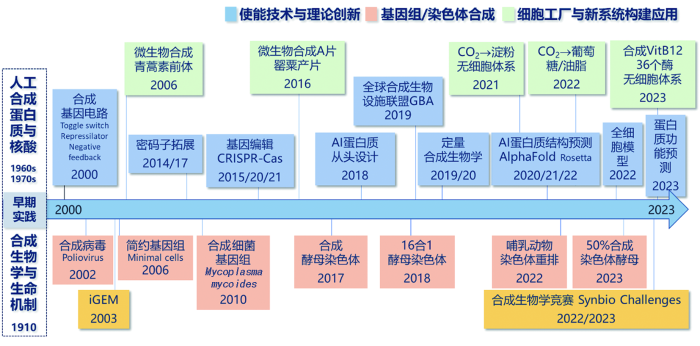
2.1 使能技术的发展与突破
使能技术(enabling technology)是指可以获得广泛应用,提升现有技术水平并获得高效益的技术[6]。合成生物使能技术的系列突破性进展,为合成生物学迅猛发展提供底层技术保证。
双稳态基因网络开关、基因振荡网络,证明了复杂代谢调控的逻辑性、人工再设计的可实现性。研究人员成功利用生物元件在微生物细胞底盘内构建逻辑线路,引入工程学理念,开启了合成生物学新的进程。2000年,波士顿大学Collins团队受噬菌体λ开关和蓝藻昼夜节律振荡器的启发,设计合成了双稳态基因网络开关,含有这种开关的细胞可以在两种稳定的表达状态之间切换,以响应外部信号[7];普林斯顿大学Elowitz和Leibler基于负反馈调控原理设计了基因振荡网络,这种被称为阻遏因子的回路的激活导致了阻遏因子蛋白表达的有序、周期性振荡[8]。这些人工生物器件和回路在大肠杆菌细胞中的实现,为基因组编辑及人工基因网络调控提供了设计思想,成为合成生物学的经典之作。随后一系列生物元件的应用,人们实现了更为复杂的人造基因线路设计。中国科学院深圳先进技术研究院娄春波团队与北京大学欧阳颀团队长期致力于探索基因回路的设计原理,其团队秉承绝缘化、正交化的设计思路,创制高质量的基因元件,并在原核生物以及真核细胞底盘上实现了鲁棒且可预测的基因回路设计[9-10]。随着人类对大规模且可预测的基因回路设计能力不断提升,科学家不仅能够精确控制单一种类细胞的行为,还可以对细胞群体进行编程,实现人工合成的微生物群落[11]。
遗传密码子的拓展、含非天然氨基酸蛋白质的合成、镜像转录的实现,开创了生命体的新形式及应用前景。2014年,斯克利普斯研究所Romesberg团队设计合成一个非天然碱基配对,实现遗传密码子的拓展,这意味着在控制条件下,未来的生命形式有无限种可能[12]。三年后,Romesberg团队又成功地使含非天然碱基dNaM-dTPT3配对的DNA在大肠杆菌中实现转录和翻译,并使非天然氨基酸在绿色荧光蛋白中定位结合[13]。北京大学陈鹏与季雄团队借助遗传密码子拓展策略,发展了一种具有单氨基酸位点分辨率的多组学技术,实现了活细胞中染色质化学修饰的编码表达与串联解析,将在细胞“代谢-修饰-基因转录”调控轴中发挥重要作用[14]。清华大学朱听团队在镜像生命研究方向开展系列工作,实现“镜像”T7转录,拓宽其在诊断治疗等方面的应用[15]。
基因组编辑、基因模块的挖掘与解析、生物体系的模拟与设计,丰富了合成生物学的底层技术。基于CRISPR系统的基因编辑工具在合成生物学中得到了广泛应用[16]。2012年,柏林马克斯·普朗克病原体科学研究所Emmanuelle Charpentier与加州大学伯克利分校Jennifer A. Doudna发现CRISPR-Cas9系统可靶向切割DNA并阐明其机制,为CRISPR-Cas9基因编辑技术建立作出了奠基性的贡献,为此二人被授予2020年诺贝尔化学奖[17]。2019年,哈佛大学David Liu团队融合人工核酸酶与逆转录酶,成功构建了引导编辑器(prime editor),开发了可在哺乳动物细胞中实现12种类型碱基置换、多碱基变换以及小片段的插入或删除的引导编辑系统。David Liu团队还接连开发了胞嘧啶碱基编辑器(cytosine base editor)和腺嘌呤碱基编辑器(adenine base editor),通过不依赖DNA双链断裂的碱基编辑技术实现了部分碱基类型的精准编辑(即碱基编辑)。除上述主要基因或碱基编辑技术策略外,2019年以来,基于CRISPR相关转座元件(CRISPR-associated transposons,CASTs)基因写入技术也有了较快发展[18]。
基于计算机辅助系统的逻辑线路构建,加速了合成生物学标准化、特征化和自动化的实现。2016年,麻省理工学院Christopher Voigt团队发表了基于端到端计算机辅助设计的Cello系统,用于在大肠杆菌中构建逻辑电路[19],通过标准化、特征化和自动化设计来实现生物化的工程化改造,实现更优地编写、构建、编辑和共享DNA代码。Voigt团队的系列工作为合成生物学领域提供了众多元件的设计算法,同时开发了多样的元件库,并提供详细的表征数据[20]。高性能计算为建模和预测开辟了新的领域。华盛顿大学David Baker团队开展系列工作,在蛋白质理性设计方面取得突飞猛进的进展。2018年,Baker团队首次完全从头开始构建出一种能够结合DFHBI荧光化合物的β桶状蛋白,其可以高精准和高亲和力地结合并作用于特定的小分子靶标上[21];随后,从头设计了自组装螺旋状蛋白质细丝,不仅能够更好地理解天然蛋白质细丝的结构和力学,同时还能创造出与自然界中完全不同的全新材料[22]。理性设计蛋白纳米机器还能够协助诊断和治疗疾病,实现对细胞更精准的控制[23]。这些工作开创了人类从头开始创建和定制复杂的跨膜蛋白的先河,使得创造自然界中不存在的跨膜蛋白来完成特定任务成为可能[24]。2022年初,伊利诺伊大学香槟分校Zaida Luthey-Schulten团队利用计算机模拟人造细胞,研究细胞的基本代谢过程和遗传信息加工过程,构建了只包含少数调节蛋白和RNA的全细胞模型,并且利用该模型研究了细胞的基本生命活动[25]。
人工智能的发展大大推动了合成生物学“理性设计”的进程。基于人工智能的蛋白质结构预测算法AlphaFold为蛋白质的从头设计提供了颠覆性的技术手段,展示了数据驱动范式在生命科学研究中的巨大潜力。2020年,DeepMind团队在Nature发表了AlphaFold算法的细节和表现。2021年,DeepMind团队再在Nature发表基于神经网络的新模型AlphaFold2,其预测的蛋白质结构能够达到原子水平的准确度[26]。2022年,AlphaFold已预测出超2.14亿个蛋白质结构,几乎涵盖地球上所有已知的蛋白[27]。同年,科技巨头Meta(前身为Facebook)训练了迄今为止最大的蛋白质语言模型ESMFold,并以此预测超6.17亿个蛋白质结构,其中还包括宏基因组中数百万个尚未被认知的全新结构[28]。中国科研人员在这方面也开展了系列工作。中国科学院微生物研究所吴边团队将蛋白质计算机设计的前沿方法引入酶工程的研究中,促进了复杂大分子结构设计的发展[29-30]。中国科学技术大学刘海燕团队采用数据驱动策略,开辟出一条全新的蛋白质从头设计路线[31]。北京大学鲁华与邓明华团队提出一种基于图神经网络模型的方法,利用层次图转换器捕捉结构信息,实现了自动而准确地推断蛋白质功能[32]。
基于数学物理模型解析生物网络拓扑结构与功能的定量关系,为理解与设计人工基因回路提供了理论框架。合成生物学的核心科学问题:一是解答生命功能跨层次涌现的原理,二是基于涌性原理解决生命系统的理性设计与构建问题[33]。为回答这一科学问题,研究人员提出定量合成生物学这一新方向。2019年,中国科学家首次提出“定量合成生物学”的概念,并于2021年组织“定量合成生物学”香山科学会议,形成“‘黑箱’理论与人工智能”与“多尺度‘白箱’定量理论”等重要思路和共识。合成生物学理论体系的完善将为回答其基本科学问题提供重要理论指导。
2.2 基因组合成与组装能力的迭代提升
生物体基因组合成与组装能力迭代提升,逐步实现原核生物基因组和酵母染色体的合成,正在挑战多细胞生物染色体合成,支撑合成生物学研究和推动下游产业转化。
人工合成病毒、细菌及酵母等微生物基因组,实现了大规模人工合成生命遗传物质的突破;简约基因组的开发,为认识基因组功能和构建底盘细胞提供了新的思路。2002年,纽约州立大学石溪市分校Wimmer团队通过化学合成病毒基因组获得了具有感染性的脊髓灰质炎病毒,也是首个人工合成的生命体[34]。继最简基因组(minimal cells)概念提出后[35],2010年,美国JCVI团队合成首个“人工合成基因组细胞”——JCVI-syn1.0[36];之后,从syn1.0的基因组中去除DNA片段,在2016年获得了更为精简syn3.0,它可以通过473个基因进行代谢和繁殖,但其分裂产生的子代细胞,形状和大小却不相同[37]。2021,JCVI团队在syn3.0(473个基因)细胞中加回7个基因,使其能够整齐地分裂成均匀的球体[38]。这标志着合成生物学又向前迈出了重要一步。
合成基因组学进入真核生物领域,人工酵母基因组Sc2.0计划已产出系列代表性成果。2014年,纽约大学Jef Boeke教授领衔的研究团队创建出了第一条人工酵母染色体(酵母染色体中最小的3号染色体)[39]。2017年,Sc2.0计划向前迈进一大步,酵母基因组中的三分之一完成了设计合成,Science以特刊形式进行了报道[40-41]。2023年,Sc2.0计划再次取得突破,实现酿酒酵母的16条染色体全部合成成功,并分别创造出了16种部分合成的酵母菌株,即每种细胞内包含15条天然染色体和1条合成染色体[42⇓-44],Cell以封面故事形式进行报道。“16合1”染色体酵母[45]和“16合2”染色体酵母[46]等成果的发布,也为研究生命本质开辟新的方向。
继实现原核生物基因组与真核生物染色体合成组装之后,科学家正在挑战多细胞生物染色体合成。2022年,中国科学院动物研究所李伟与周琪团队实现了哺乳动物完整染色体的可编程连接,并创建出具有全新核型(染色体组型)的小鼠[47]。研究人员利用小鼠单倍体胚胎干细胞和CRISPR基因编辑工具,成功将最长的染色体1号和2号进行正反连接,以及将中等长度的5号和4号染色体进行首尾连接(实验小鼠未表现出明显异常)。结果表明,来自小鼠的两条独立存在的染色体在基因编辑后,可以以非同源末端连接修复的方式连接为一条染色体。这项工作拓展了“造物致知”的合成生物学研究策略,并奠定了相应的技术平台。
2.3 细胞工厂和新生物系统的构建与应用
使能技术的系列突破,为解析生命运行规律提供了全新的手段,并加快了合成生物学的工程化应用;生物体基因组合成与组装能力迭代提升,支撑合成生物学研究和推动下游产业转化。
维生素B12等新领域精细化工产品的无细胞体系合成,突破了以微生物为底盘的系列困难。2023年,中国科学院天津工业生物技术研究所张大伟团队将微生物B12合成途径中的24步催化反应进行模块划分,通过组装36个酶的体外多酶催化系统,实现了以5-氨基乙酰丙酸(5-ALA)为底物合成维生素B12体系构建,及以HBA为底物合成维生素B12催化体系的产量提升[54]。
此外,合成生物学的发展离不开青年后备力量的培育。国际基因工程机器大赛(International Genetically Engineered Machine Competition,iGEM)自2003年成立至今,30年间培育了一大批青年科学家与一些有影响力的合成生物企业,形成了广泛的社会影响。中国的合成生物学竞赛(Synbio Challenges)创办于2022年,开局良好,逐步走向国际化。这些都将为合成生物学、生命科学、交叉学科培养后备生力军。
3 合成生物学体系渐成
年来,合成生物学取得长足发展,成就显著(图1),逐渐减少对其他工程学科理论与实践的路径依赖。科学家对生命机制的理性探索(如基因网络调控原理和逻辑门的设计等)、多学科的介入(如系统生物学、工程学、化学生物学、计算机科学等)、相关领域(如遗传学及基因组学、微生物学及代谢工程学、生物化工与工程学等)专家的远见和执着驱动合成生物学快速发展,学科体系渐成。合成生物学基于基础理论指导,采取“自下而上”的工程学方法,发展使能技术,并解决生物体系工程化应用“标准化”与缺乏理性设计的难题,其学科体系主要涵盖基础理论、使能技术、创新应用等方面。与此同时,合成生物学的发展应同步关注与其适配的政策环境,伦理、政策与法律框架,注重科学普及公众参与(图2)。
图2

合成生物学基础理论包括两个方面:一是传统“定量生物学”方法,即通过定量表征组元和数理演绎建模的方法,构建知识驱动的“白箱模型”;二是从生物大数据出发,运用机器学习等“人工智能”方法加以统计归纳,构建数据驱动的“黑箱模型”。第一类方法适合循序渐进地增加系统的复杂度,而第二类方法则直接从成功案例中提取生命过程内在的结构和关联。
合成生物使能技术包括基因测序、基因组合成与组装,新一代基因组编辑技术,蛋白质设计工程(生物大分子工程、进化与设计),基因线路与细胞工程,无细胞体系,多细胞体系,非天然编码与杂合生物体系、正交生物体系等。此外,生物自动化铸造工厂以及器件资源信息平台在合成生物学的发展中发挥越来越重要的作用[6]。
合成生物学的创新应用,包括两个层面,即“造物致知,造物致用”。造物致知是指构建生命体系(如人工细胞全合成),理解生物功能涌现及其底层原理。造物致用是指通过创造生物体系推动生物技术迭代发展及未来生物经济和可持续发展,其创新应用领域主要包括生物工业、生物医学、生物农业与未来食品、环境生物技术、生物与信息交叉技术(如生物传感、DNA存储)及地外生物等。
合成生物学的发展离不开良好的政策与监管环境。合成生物科技发展与产业创新应用的同时,需兼顾考虑生物伦理、生物安全、生物安保、监管、教育、公众参与等方面。简言之,科普教育、政策伦理和法规制定与合成生物科技与产业发展相伴而行,持续探讨和主动解决其潜在问题,为合成生物学健康发展保驾护航。随着理论、技术与应用的多轮驱动发展,合成生物学的学科体系将日臻完善。
4 总结与展望
生命科学的进步推动人类社会发展的进程。合成生物学通过构建生物体系可以更好地理解生命,也可以更好地服务人类,在生命科学和生物技术方面都具有重要意义。合成生物学体系的构建不仅推动生物工程应用的革命性发展,也为生命科学基础研究带来了崭新机遇。但是,当前合成生物学的发展也面临若干挑战,如全细胞模拟设计、人工细胞合成、实时生物传感、DNA设计的深度学习、定制和动态合成基因组、细胞群落和多细胞群落构建、为可持续性目标而设计的生物体等[61],需从理论与技术层面实现突破。
合成生物学未来的发展将受到多个关键因素的推动,每个因素都将为合成生物学体系的搭建和应用赋能提供前所未有的动力。首先,生命科学领域的发现和突破,为合成生物学的开创性发展奠定基础,揭示生物系统复杂性的新认知。其次,合成生物学定量理论的发展将进一步增强对生命机制与规律的理解,为“造物致知”和“造物致用”提供理论指导。再次,合成生物的底层工具和共性技术的不断迭代将重塑这一领域,使研究人员能够以更精准、高效的方式工程化生物体系。最后,由人工智能驱动的合成生物科技与产业将带来变革性的力量,大幅提升生物工具设计创制的能力、速度、精度,为合成生物研发与应用提供超乎想象的机遇,其影响涵盖从个性化医学到可持续生物制造的多个领域,最终将形塑一个理论突破、技术创新与赋能增效相互交织的未来。
参考文献
世界生命科学格局中的中国
China in global landscape of life sciences
中国合成生物学发展回顾与展望
Synthetic biology in China: review and prospects
合成生物学: 开启生命科学“会聚” 研究新时代
Synthetic biology: unsealing the convergence era of life science research
A brief history of synthetic biology

The ability to rationally engineer microorganisms has been a long-envisioned goal dating back more than a half-century. With the genomics revolution and rise of systems biology in the 1990s came the development of a rigorous engineering discipline to create, control and programme cellular behaviour. The resulting field, known as synthetic biology, has undergone dramatic growth throughout the past decade and is poised to transform biotechnology and medicine. This Timeline article charts the technological and cultural lifetime of synthetic biology, with an emphasis on key breakthroughs and future challenges.
Enabling technology and core theory of synthetic biology
Construction of a genetic toggle switch in Escherichia coli
A synthetic oscillatory network of transcriptional regulators
Insulated transcriptional elements enable precise design of genetic circuits
Rational engineering of biological systems is often complicated by the complex but unwanted interactions between cellular components at multiple levels. Here we address this issue at the level of prokaryotic transcription by insulating minimal promoters and operators to prevent their interaction and enable the biophysical modeling of synthetic transcription without free parameters. This approach allows genetic circuit design with extraordinary precision and diversity, and consequently simplifies the design-build-test-learn cycle of circuit engineering to a mix-and-match workflow. As a demonstration, combinatorial promoters encoding NOT-gate functions were designed from scratch with mean errors of <1.5-fold and a success rate of >96% using our insulated transcription elements. Furthermore, four-node transcriptional networks with incoherent feed-forward loops that execute stripe-forming functions were obtained without any trial-and-error work. This insulation-based engineering strategy improves the resolution of genetic circuit technology and provides a simple approach for designing genetic circuits for systems and synthetic biology.
Precise programming of multigene expression stoichiometry in mammalian cells by a modular and programmable transcriptional system
Context-dependency of mammalian transcriptional elements has hindered the quantitative investigation of multigene expression stoichiometry and its biological functions. Here, we describe a host- and local DNA context-independent transcription system to gradually fine-tune single and multiple gene expression with predictable stoichiometries. The mammalian transcription system is composed of a library of modular and programmable promoters from bacteriophage and its cognate RNA polymerase (RNAP) fused to a capping enzyme. The relative expression of single genes is quantitatively determined by the relative binding affinity of the RNAP to the promoters, while multigene expression stoichiometry is predicted by a simple biochemical model with resource competition. We use these programmable and modular promoters to predictably tune the expression of three components of an influenza A virus-like particle (VLP). Optimized stoichiometry leads to a 2-fold yield of intact VLP complexes. The host-independent orthogonal transcription system provides a platform for dose-dependent control of multiple protein expression which may be applied for advanced vaccine engineering, cell-fate programming and other therapeutic applications.© 2023. The Author(s).
Emergent genetic oscillations in a synthetic microbial consortium
A challenge of synthetic biology is the creation of cooperative microbial systems that exhibit population-level behaviors. Such systems use cellular signaling mechanisms to regulate gene expression across multiple cell types. We describe the construction of a synthetic microbial consortium consisting of two distinct cell types—an "activator" strain and a "repressor" strain. These strains produced two orthogonal cell-signaling molecules that regulate gene expression within a synthetic circuit spanning both strains. The two strains generated emergent, population-level oscillations only when cultured together. Certain network topologies of the two-strain circuit were better at maintaining robust oscillations than others. The ability to program population-level dynamics through the genetic engineering of multiple cooperative strains points the way toward engineering complex synthetic tissues and organs with multiple cell types.Copyright © 2015, American Association for the Advancement of Science.
A semi-synthetic organism with an expanded genetic alphabet
A semi-synthetic organism that stores and retrieves increased genetic information
Linking chromatin acylation mark-defined proteome and genome in living cells
A generalizable strategy with programmable site specificity for in situ profiling of histone modifications on unperturbed chromatin remains highly desirable but challenging. We herein developed a single-site-resolved multi-omics (SiTomics) strategy for systematic mapping of dynamic modifications and subsequent profiling of chromatinized proteome and genome defined by specific chromatin acylations in living cells. By leveraging the genetic code expansion strategy, our SiTomics toolkit revealed distinct crotonylation (e.g., H3K56cr) and β-hydroxybutyrylation (e.g., H3K56bhb) upon short chain fatty acids stimulation and established linkages for chromatin acylation mark-defined proteome, genome, and functions. This led to the identification of GLYR1 as a distinct interacting protein in modulating H3K56cr's gene body localization as well as the discovery of an elevated super-enhancer repertoire underlying bhb-mediated chromatin modulations. SiTomics offers a platform technology for elucidating the "metabolites-modification-regulation" axis, which is widely applicable for multi-omics profiling and functional dissection of modifications beyond acylations and proteins beyond histones.Copyright © 2023 Elsevier Inc. All rights reserved.
7 transcription of chirally inverted ribosomal and functional RNAs
\n To synthesize a chirally inverted ribosome with the goal of building mirror-image biology systems requires the preparation of kilobase-long mirror-image ribosomal RNAs that make up the structural and catalytic core and about two-thirds of the molecular mass of the mirror-image ribosome. Here, we chemically synthesized a 100-kilodalton mirror-image T7 RNA polymerase, which enabled efficient and faithful transcription of the full-length mirror-image 5\n S\n, 16\n S\n, and 23\n S\n ribosomal RNAs from enzymatically assembled long mirror-image genes. We further exploited the versatile mirror-image T7 transcription system for practical applications such as biostable mirror-image riboswitch sensor, long-term storage of unprotected kilobase-long\n l\n -RNA in water, and\n l\n -ribozyme–catalyzed\n l\n -RNA polymerization to serve as a model system for basic RNA research.\n
CRISPR technology: a decade of genome editing is only the beginning
The advent of clustered regularly interspaced short palindromic repeat (CRISPR) genome editing, coupled with advances in computing and imaging capabilities, has initiated a new era in which genetic diseases and individual disease susceptibilities are both predictable and actionable. Likewise, genes responsible for plant traits can be identified and altered quickly, transforming the pace of agricultural research and plant breeding. In this Review, we discuss the current state of CRISPR-mediated genetic manipulation in human cells, animals, and plants along with relevant successes and challenges and present a roadmap for the future of this technology.
A programmable dual-RNA-guided DNA endonuclease in adaptive bacterial immunity
Clustered regularly interspaced short palindromic repeats (CRISPR)/CRISPR-associated (Cas) systems provide bacteria and archaea with adaptive immunity against viruses and plasmids by using CRISPR RNAs (crRNAs) to guide the silencing of invading nucleic acids. We show here that in a subset of these systems, the mature crRNA that is base-paired to trans-activating crRNA (tracrRNA) forms a two-RNA structure that directs the CRISPR-associated protein Cas9 to introduce double-stranded (ds) breaks in target DNA. At sites complementary to the crRNA-guide sequence, the Cas9 HNH nuclease domain cleaves the complementary strand, whereas the Cas9 RuvC-like domain cleaves the noncomplementary strand. The dual-tracrRNA:crRNA, when engineered as a single RNA chimera, also directs sequence-specific Cas9 dsDNA cleavage. Our study reveals a family of endonucleases that use dual-RNAs for site-specific DNA cleavage and highlights the potential to exploit the system for RNA-programmable genome editing.
Molecular mechanism for Tn7-like transposon recruitment by a type I-B CRISPR effector
Tn7-like transposons have co-opted CRISPR-Cas systems to facilitate the movement of their own DNA. These CRISPR-associated transposons (CASTs) are promising tools for programmable gene knockin. A key feature of CASTs is their ability to recruit Tn7-like transposons to nuclease-deficient CRISPR effectors. However, how Tn7-like transposons are recruited by diverse CRISPR effectors remains poorly understood. Here, we present the cryo-EM structure of a recruitment complex comprising the Cascade complex, TniQ, TnsC, and the target DNA in the type I-B CAST from Peltigera membranacea cyanobiont 210A. Target DNA recognition by Cascade induces conformational changes in Cas6 and primes TniQ recruitment through its C-terminal domain. The N-terminal domain of TniQ is bound to the seam region of the TnsC spiral heptamer. Our findings provide insights into the diverse mechanisms for the recruitment of Tn7-like transposons to CRISPR effectors and will aid in the development of CASTs as gene knockin tools.Copyright © 2023 Elsevier Inc. All rights reserved.
Genetic circuit design automation
\n As synthetic biology techniques become more powerful, researchers are anticipating a future in which the design of biological circuits will be similar to the design of integrated circuits in electronics. Nielsen\n et al.\n describe what is essentially a programming language to design computational circuits in living cells. The circuits generated on plasmids expressed in\n Escherichia coli\n required careful insulation from their genetic context, but primarily functioned as specified. The circuits could, for example, regulate cellular functions in response to multiple environmental signals. Such a strategy can facilitate the development of more complex circuits by genetic engineering.\n
The second decade of synthetic biology: 2010-2020
De novo design of a fluorescence-activating β-barrel
De novo design of self-assembling helical protein filaments
We describe a general computational approach to designing self-assembling helical filaments from monomeric proteins and use this approach to design proteins that assemble into micrometer-scale filaments with a wide range of geometries in vivo and in vitro. Cryo-electron microscopy structures of six designs are close to the computational design models. The filament building blocks are idealized repeat proteins, and thus the diameter of the filaments can be systematically tuned by varying the number of repeat units. The assembly and disassembly of the filaments can be controlled by engineered anchor and capping units built from monomers lacking one of the interaction surfaces. The ability to generate dynamic, highly ordered structures that span micrometers from protein monomers opens up possibilities for the fabrication of new multiscale metamaterials.Copyright © 2018 The Authors, some rights reserved; exclusive licensee American Association for the Advancement of Science. No claim to original U.S. Government Works.
Programmable design of orthogonal protein heterodimers
Accurate computational design of multipass transmembrane proteins
The computational design of transmembrane proteins with more than one membrane-spanning region remains a major challenge. We report the design of transmembrane monomers, homodimers, trimers, and tetramers with 76 to 215 residue subunits containing two to four membrane-spanning regions and up to 860 total residues that adopt the target oligomerization state in detergent solution. The designed proteins localize to the plasma membrane in bacteria and in mammalian cells, and magnetic tweezer unfolding experiments in the membrane indicate that they are very stable. Crystal structures of the designed dimer and tetramer-a rocket-shaped structure with a wide cytoplasmic base that funnels into eight transmembrane helices-are very close to the design models. Our results pave the way for the design of multispan membrane proteins with new functions.Copyright © 2018 The Authors, some rights reserved; exclusive licensee American Association for the Advancement of Science. No claim to original U.S. Government Works.
Fundamental behaviors emerge from simulations of a living minimal cell
We present a whole-cell fully dynamical kinetic model (WCM) of JCVI-syn3A, a minimal cell with a reduced genome of 493 genes that has retained few regulatory proteins or small RNAs. Cryo-electron tomograms provide the cell geometry and ribosome distributions. Time-dependent behaviors of concentrations and reaction fluxes from stochastic-deterministic simulations over a cell cycle reveal how the cell balances demands of its metabolism, genetic information processes, and growth, and offer insight into the principles of life for this minimal cell. The energy economy of each process including active transport of amino acids, nucleosides, and ions is analyzed. WCM reveals how emergent imbalances lead to slowdowns in the rates of transcription and translation. Integration of experimental data is critical in building a kinetic model from which emerges a genome-wide distribution of mRNA half-lives, multiple DNA replication events that can be compared to qPCR results, and the experimentally observed doubling behavior.Copyright © 2021 The Author(s). Published by Elsevier Inc. All rights reserved.
Highly accurate protein structure prediction with AlphaFold
Proteins are essential to life, and understanding their structure can facilitate a mechanistic understanding of their function. Through an enormous experimental effort1–4, the structures of around 100,000 unique proteins have been determined5, but this represents a small fraction of the billions of known protein sequences6,7. Structural coverage is bottlenecked by the months to years of painstaking effort required to determine a single protein structure. Accurate computational approaches are needed to address this gap and to enable large-scale structural bioinformatics. Predicting the three-dimensional structure that a protein will adopt based solely on its amino acid sequence—the structure prediction component of the ‘protein folding problem’8—has been an important open research problem for more than 50 years9. Despite recent progress10–14, existing methods fall far short of atomic accuracy, especially when no homologous structure is available. Here we provide the first computational method that can regularly predict protein structures with atomic accuracy even in cases in which no similar structure is known. We validated an entirely redesigned version of our neural network-based model, AlphaFold, in the challenging 14th Critical Assessment of protein Structure Prediction (CASP14)15, demonstrating accuracy competitive with experimental structures in a majority of cases and greatly outperforming other methods. Underpinning the latest version of AlphaFold is a novel machine learning approach that incorporates physical and biological knowledge about protein structure, leveraging multi-sequence alignments, into the design of the deep learning algorithm.
‘The entire protein universe’: AI predicts shape of nearly every known protein
Evolutionary-scale prediction of atomic-level protein structure with a language model
Recent advances in machine learning have leveraged evolutionary information in multiple sequence alignments to predict protein structure. We demonstrate direct inference of full atomic-level protein structure from primary sequence using a large language model. As language models of protein sequences are scaled up to 15 billion parameters, an atomic-resolution picture of protein structure emerges in the learned representations. This results in an order-of-magnitude acceleration of high-resolution structure prediction, which enables large-scale structural characterization of metagenomic proteins. We apply this capability to construct the ESM Metagenomic Atlas by predicting structures for >617 million metagenomic protein sequences, including >225 million that are predicted with high confidence, which gives a view into the vast breadth and diversity of natural proteins.
Development of a versatile and efficient C-N lyase platform for asymmetric hydroamination via computational enzyme redesign
Computational redesign of a PETase for plastic biodegradation under ambient condition by the GRAPE strategy
A backbone-centred energy function of neural networks for protein design
Hierarchical graph transformer with contrastive learning for protein function prediction
In recent years, high-throughput sequencing technologies have made large-scale protein sequences accessible. However, their functional annotations usually rely on low-throughput and pricey experimental studies. Computational prediction models offer a promising alternative to accelerate this process. Graph neural networks have shown significant progress in protein research, but capturing long-distance structural correlations and identifying key residues in protein graphs remains challenging.
合成生物学的科学问题
Scientific questions for synthetic biology
Chemical synthesis of poliovirus cDNA: generation of infectious virus in the absence of natural template
Full-length poliovirus complementary DNA (cDNA) was synthesized by assembling oligonucleotides of plus and minus strand polarity. The synthetic poliovirus cDNA was transcribed by RNA polymerase into viral RNA, which translated and replicated in a cell-free extract, resulting in the de novo synthesis of infectious poliovirus. Experiments in tissue culture using neutralizing antibodies and CD155 receptor-specific antibodies and neurovirulence tests in CD155 transgenic mice confirmed that the synthetic virus had biochemical and pathogenic characteristics of poliovirus. Our results show that it is possible to synthesize an infectious agent by in vitro chemical-biochemical means solely by following instructions from a written sequence.
Evolution of a minimal cell
Possessing only essential genes, a minimal cell can reveal mechanisms and processes that are critical for the persistence and stability of life1,2. Here we report on how an engineered minimal cell3,4 contends with the forces of evolution compared with the Mycoplasma mycoides non-minimal cell from which it was synthetically derived. Mutation rates were the highest among all reported bacteria, but were not affected by genome minimization. Genome streamlining was costly, leading to a decrease in fitness of greater than 50%, but this deficit was regained during 2,000 generations of evolution. Despite selection acting on distinct genetic targets, increases in the maximum growth rate of the synthetic cells were comparable. Moreover, when performance was assessed by relative fitness, the minimal cell evolved 39% faster than the non-minimal cell. The only apparent constraint involved the evolution of cell size. The size of the non-minimal cell increased by 80%, whereas the minimal cell remained the same. This pattern reflected epistatic effects of mutations in ftsZ, which encodes a tubulin-homologue protein that regulates cell division and morphology5,6. Our findings demonstrate that natural selection can rapidly increase the fitness of one of the simplest autonomously growing organisms. Understanding how species with small genomes overcome evolutionary challenges provides critical insights into the persistence of host-associated endosymbionts, the stability of streamlined chassis for biotechnology and the targeted refinement of synthetically engineered cells2,7–9.
Creation of a bacterial cell controlled by a chemically synthesized genome
We report the design, synthesis, and assembly of the 1.08-mega-base pair Mycoplasma mycoides JCVI-syn1.0 genome starting from digitized genome sequence information and its transplantation into a M. capricolum recipient cell to create new M. mycoides cells that are controlled only by the synthetic chromosome. The only DNA in the cells is the designed synthetic DNA sequence, including "watermark" sequences and other designed gene deletions and polymorphisms, and mutations acquired during the building process. The new cells have expected phenotypic properties and are capable of continuous self-replication.
Design and synthesis of a minimal bacterial genome
\n A goal in biology is to understand the molecular and biological function of every gene in a cell. One way to approach this is to build a minimal genome that includes only the genes essential for life. In 2010, a 1079-kb genome based on the genome of\n Mycoplasma mycoides\n (JCV-syn1.0) was chemically synthesized and supported cell growth when transplanted into cytoplasm. Hutchison III\n et al.\n used a design, build, and test cycle to reduce this genome to 531 kb (473 genes). The resulting JCV-syn3.0 retains genes involved in key processes such as transcription and translation, but also contains 149 genes of unknown function.\n
Genetic requirements for cell division in a genomically minimal cell
Total synthesis of a functional designer eukaryotic chromosome
Rapid advances in DNA synthesis techniques have made it possible to engineer viruses, biochemical pathways and assemble bacterial genomes. Here, we report the synthesis of a functional 272,871-base pair designer eukaryotic chromosome, synIII, which is based on the 316,617-base pair native Saccharomyces cerevisiae chromosome III. Changes to synIII include TAG/TAA stop-codon replacements, deletion of subtelomeric regions, introns, transfer RNAs, transposons, and silent mating loci as well as insertion of loxPsym sites to enable genome scrambling. SynIII is functional in S. cerevisiae. Scrambling of the chromosome in a heterozygous diploid reveals a large increase in a-mater derivatives resulting from loss of the MATα allele on synIII. The complete design and synthesis of synIII establishes S. cerevisiae as the basis for designer eukaryotic genome biology.
Design of a synthetic yeast genome
We describe complete design of a synthetic eukaryotic genome, Sc2.0, a highly modified genome reduced in size by nearly 8%, with 1.1 megabases of the synthetic genome deleted, inserted, or altered. Sc2.0 chromosome design was implemented with BioStudio, an open-source framework developed for eukaryotic genome design, which coordinates design modifications from nucleotide to genome scales and enforces version control to systematically track edits. To achieve complete Sc2.0 genome synthesis, individual synthetic chromosomes built by Sc2.0 Consortium teams around the world will be consolidated into a single strain by "endoreduplication intercross." Chemically synthesized genomes like Sc2.0 are fully customizable and allow experimentalists to ask otherwise intractable questions about chromosome structure, function, and evolution with a bottom-up design strategy.Copyright © 2017, American Association for the Advancement of Science.
Debugging and consolidating multiple synthetic chromosomes reveals combinatorial genetic interactions
Design, construction, and functional characterization of a tRNA neochromosome in yeast
A spotlight on global collaboration in the Sc2.0 yeast consortium
Creating a functional single-chromosome yeast
Karyotype engineering by chromosome fusion leads to reproductive isolation in yeast
A sustainable mouse karyotype created by programmed chromosome fusion
Chromosome engineering has been attempted successfully in yeast but remains challenging in higher eukaryotes, including mammals. Here, we report programmed chromosome ligation in mice that resulted in the creation of new karyotypes in the lab. Using haploid embryonic stem cells and gene editing, we fused the two largest mouse chromosomes, chromosomes 1 and 2, and two medium-size chromosomes, chromosomes 4 and 5. Chromatin conformation and stem cell differentiation were minimally affected. However, karyotypes carrying fused chromosomes 1 and 2 resulted in arrested mitosis, polyploidization, and embryonic lethality, whereas a smaller fused chromosome composed of chromosomes 4 and 5 was able to be passed on to homozygous offspring. Our results suggest the feasibility of chromosome-level engineering in mammals.
Production of the antimalarial drug precursor artemisinic acid in engineered yeast
Complete biosynthesis of cannabinoids and their unnatural analogues in yeast
Engineering yeast for the de novo synthesis of jasmonates
Complete biosynthesis of opioids in yeast
Opioids are the primary drugs used in Western medicine for pain management and palliative care. Farming of opium poppies remains the sole source of these essential medicines, despite diverse market demands and uncertainty in crop yields due to weather, climate change, and pests. We engineered yeast to produce the selected opioid compounds thebaine and hydrocodone starting from sugar. All work was conducted in a laboratory that is permitted and secured for work with controlled substances. We combined enzyme discovery, enzyme engineering, and pathway and strain optimization to realize full opiate biosynthesis in yeast. The resulting opioid biosynthesis strains required the expression of 21 (thebaine) and 23 (hydrocodone) enzyme activities from plants, mammals, bacteria, and yeast itself. This is a proof of principle, and major hurdles remain before optimization and scale-up could be achieved. Open discussions of options for governing this technology are also needed in order to responsibly realize alternative supplies for these medically relevant compounds. Copyright © 2015, American Association for the Advancement of Science.
Cell-free chemoenzymatic starch synthesis from carbon dioxide
[Figure: see text].
Upcycling CO2 into energy-rich long-chain compounds via electrochemical and metabolic engineering
A synthetic cell-free 36-enzyme reaction system for vitamin B12 production
Adenosylcobalamin (AdoCbl), a biologically active form of vitamin B12 (coenzyme B12), is one of the most complex metal-containing natural compounds and an essential vitamin for animals. However, AdoCbl can only be de novo synthesized by prokaryotes, and its industrial manufacturing to date was limited to bacterial fermentation. Here, we report a method for the synthesis of AdoCbl based on a cell-free reaction system performing a cascade of catalytic reactions from 5-aminolevulinic acid (5-ALA), an inexpensive compound. More than 30 biocatalytic reactions are integrated and optimized to achieve the complete cell-free synthesis of AdoCbl, after overcoming feedback inhibition, the complicated detection, instability of intermediate products, as well as imbalance and competition of cofactors. In the end, this cell-free system produces 417.41 μg/L and 5.78 mg/L of AdoCbl using 5-ALA and the purified intermediate product hydrogenobyrate as substrates, respectively. The strategies of coordinating synthetic modules of complex cell-free system describe here will be generally useful for developing cell-free platforms to produce complex natural compounds with long and complicated biosynthetic pathways.
Engineered living materials for sustainability
Engineering Halomonas bluephagenesis as a chassis for bioproduction from starch
Materials design by synthetic biology
DNA storage: research landscape and future prospects
The global demand for data storage is currently outpacing the world's storage capabilities. DNA, the carrier of natural genetic information, offers a stable, resource- and energy-efficient and sustainable data storage solution. In this review, we summarize the fundamental theory, research history, and technical challenges of DNA storage. From a quantitative perspective, we evaluate the prospect of DNA, and organic polymers in general, as a novel class of data storage medium.© The Author(s) 2020. Published by Oxford University Press on behalf of China Science Publishing & Media Ltd.
Biosensors for the detection of Bacillus anthracis
Biosensors applications in medical field: a brief review
Ten future challenges for synthetic biology
Building a global alliance of biofoundries
Biofoundries provide an integrated infrastructure to enable the rapid design, construction, and testing of genetically reprogrammed organisms for biotechnology applications and research. Many biofoundries are being built and a Global Biofoundry Alliance has recently been established to coordinate activities worldwide.

{kind=link}
{kind=link}
{kind=link}
{kind=link}